Конечно, довольно трудно захватывать другие, неизвестные ниши. Очень частый случай — человек приобрел видеокамеру, более-менее освоил тот или иной пакет монтажа, но о звуке как-то и забыл. Потом его работы можно смотреть только на домашнем DVD и то, значительно увеличивая громкость, слушая шумы, забивающую все музыку и так далее. Это встречается чуть ли не повсюду. Поэтому звук нужно знать хорошо, хоть это и отдельная, на самом деле сложная техническая специализация.
Поэтому мы выделим только необходимые моменты, и давайте начнем с терминологии, вернее, с перевода звуковых понятий на более понятный язык видео.
Основные звуковые термины, которые нужно будет знать
Итак, 24 кадра в кино — это стандарт, который позволяет создать видимость непрерывного действия путем смены статических кадров. То есть, вы снимаете движение, а зритель потом его видит и воспринимает именно как движение. В звуке картина примерно схожая.
Звук — упругие колебания воздушной среды. Обычно их можно представить на графике в виде волны сложной формы (эта сложная волна состоит из ряда простых синусоид и косинусоид различных частот). Частота акустической волны в слышимом частотном диапазоне (составляющем интервал от 20 Гц до 20 КГц нами) воспринимается как высота звучания. То есть, чем больше частота, тем выше мы ее слышим.
Поскольку все природные звуки являются сложными по структуре, то мы можем говорить о диапазонах волн. Например, человеческий голос находится в спектре от 100 Гц до 3-4 КГц, там же находится и множество других музыкальных инструментов.
График звуковой волны — это взаимосвязь изменения амплитуды звукового давления в процессе времени. И именно этот график можно считать аналоговым сигналом. То есть, то что происходит в воздушной среде переносится на какой-нибудь носитель (слово «аналоговый», это тоже самое, что и «аналогичный»). То есть, если очень простыми словами, фактически нет разницы между формой волны, передающейся по проводам, формой волны, являющейся дорожкой на виниловой пластинке и так далее. Цифровой звуковой сигнал — это фактически цифровая копия аналогового, которая записывается в виде точек, в которых записано текущее значение напряжения. Данные точки еще называются дискретными отсчетами, поэтом и существует такой термин как частота дискретизации. Чем она больше, тем достовернее описывается сигнал. То есть именно тут уместно сравнение с кино, частота дискретизации сравнима с частотой смены кадров. Нам нужно передать движение.
Но, есть разница между тем: вы записываете видео на дешевую камеру с небольшим количеством цветов и на более профессиональное устройство. Да, есть и видео существует такое понятие как цветовое разрешение точки (формат пикселя). Например, понятие «восьмибитная точка» говорит о количестве цветовых градаций, которое может записывать устройство. То есть, в реале есть какой-то цвет, и при записи на камеру берется не он в буквальном смысле, а находится наиболее близкий оттенок, присутствующий в гамме. В звуке все довольно похоже, только там необходима большая разрешающая способность для дискретных отсчетов. Общепринятым стандартом является 16 бит (хотя есть как меньше, так и больше).
Поэтому если в видео основными характеристиками является частота смены кадров и цветовая разрешающая способность, то в звуке им на смену используются аналогичные — частота дискретизации и разрешение.
Теперь переходим к понятиям яркости и контраста для видео. В звуке им соответствуют — уровень сигнала (громкость) и динамический диапазон (разница между самым громким и самым тихим звуками).
Сводная таблица переводов
Итак, чтобы упростить ситуацию, создадим некую небольшую таблицу:
| Видео-термины | Примерно схожие с ними звуковые термины |
| Цвет | Частота |
| Частота смены кадров | Частота дискретизации |
| Пиксель | Дискретный отсчет |
| Цветовое разрешение (формат пикселя) | Разрешение |
| Яркость | Уровень сигнала (громкость) |
| Контрастность | Динамический диапазон |
А теперь давайте попробуем эту таблицу использовать. Видеоинженер говорит: «Я хочу подчеркнуть зеленый цвет», звукорежиссер: «Я хочу подчеркнуть определенный диапазон частот». Видеоинженер: «Я выбираю частоту смены кадров PAL 25 fps», звукорежиссер: «Стандарт для цифровых преобразований будет с частотой дискретизации 48 КГц». И так далее. На самом деле, пример с переводом терминов не является ноу-хау со стороны вашего покорного слуги, поскольку попытки создания переводчиков между двумя специализациями были и раньше, в том числе и от авторов программы Vegas (тогда это была компания Sonic Foundry).
Главные правила для звукового ряда в видео
В видео практически всегда имеется главный персонаж, обычно человек. То есть его речь должна быть максимально прослушиваемой, значительно отличаться от остального звукового ряда, не иметь существенных артефактов, таких как, например, неправильное произношение, неверно выставленный уровень записи, что может привести либо к большому количеству шумов (если уровень низкий) либо искажениям (если уровень превышает предельно допустимый).
Отталкиваясь от этих правил переходим к практике.
Запись
Для преобразования акустического звука в аналоговый сигнал используются специальные преобразующие устройства — микрофоны. В зависимости от самого типа преобразователя они бывают динамическими и конденсаторными. Если вы хотите качественно записывать речь, то вам будут необходимы достаточно дорогие модели, то есть, не те которые продаются на рынках в ярких упаковках за пять долларов. Проблемы после именно таких покупок будут очевидными — низкое качество с присутствием большого количества шумов, достаточно низкий уровень сигнала.
В принципе, в большинстве камкодеров уже имеются в арсенале неплохие варианты, потому как сами устройства не дешевые. А в общем и целом, вам нужен и отдельный микрофон. Достаточно хорошую модель можно найти в диапазоне от 40 у.е., обратите внимание на продукцию таких фирм как AKG, Nady, Shure. В принципе, так дешево стоят динамические микрофоны (хорошие конденсаторные намного дороже, плюс к ним понадобится предусилитель — отдельное устройство для промежуточного усиления сигнала).
Далее вы производите подключение микрофона к звуковой карте компьютера, и проводите небольшое количество тестов. У многих часто возникает вопрос насчет самих звуковых карт и хватит ли кодека, встроенного в материнскую плату РС? Конечно, не рекомендуется его использование, хотя более-менее нормальные модели звуковых интерфейсов стоят от 150 у.е. Это может не состыковаться с вашим бюджетом. Поэтому предположим вариант с кодеком.
Запускаем Sony Vegas, создаем новый проект, в который вгружаем пустую аудио-дорожку. В ее панели управления, нажимаем кнопку Arm for Record (подготовка к записи). В результате чего в этой панели появится индикатор. Активная зеленая полоска в нем отобразит существующий уровень шума. Для кодеков он достаточно большой и составляет примерно -60 — -50 дБ. В Vegas нет регулторов уровня входящего сигнала, а они (эти регуляторы) находятся или в драйверах звуковой платы, или, в случае кодека, в звуковой панели Windows. Там вы выставляете необходимый уровень для микрофонного входа (Mic In), при недостаточном делаете активным указатель +20 дБ (усиление на 20 дБ). А общую регулировку производите так, чтобы уровень сигнала записываемой речи был как можно ближе к нулевой отметке (максимуму) в индикаторе Vegas. Но при этом, чтобы не было зашкаливания.
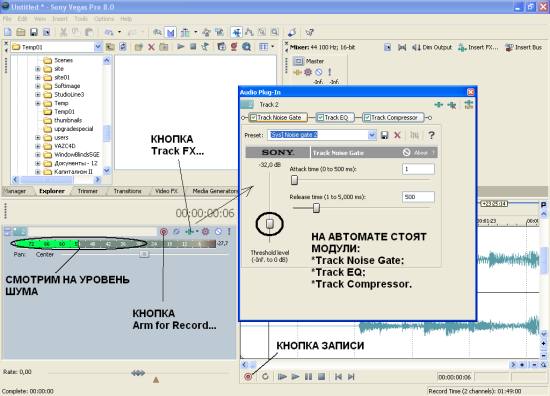
Подготовка к записи. При включении режима Arm for Record мы можем увидеть уровень шума на индикаторе. После этого входим в настройки трека и в модуле Track Noise Gate показываем это значение (тогда сигнал с уровнем ниже просто не будет записываться).
Теперь мы не станем производить запись, а сделаем следующее. В панели управления нашего аудиотрека найдем кнопку Track FX… по нажатии на которую появляется целый набор модулей, автоматически подключенный к дорожке. Нас интересует первый из них, а именно Track Noise Gate. Если объяснять простыми словами — это удаление шума с определенного уровня, то есть, в нашем примере мы этот уровень знаем, он составляет -60 — -50 дБ. Его и указываем.
После этого можем начинать запись, нажав на соответствующую кнопку в рабочей области.
Редактирование
Редактирование лучше производить в программе звуковом редакторе — Sony Sound Forge. При этой операции удаляются фрагменты дыхания, исправляются некоторые дефекты (например, одна и та же фраза проговорена несколько раз). Помимо этого там есть такой полезный модуль как Time Stratch (убыстрение/замедление). Убыстрение используется очень часто для придания динамики речи.
Если у вас нет этого редактора под рукой, то придется использовать более скромные возможности Vegas. Первый вариант — загрузка трека в модуль Trimmer и нарезка его на фрагменты. Второй — все операции проделываются сразу в рабочей области (чтобы разрезать звуковой фрагмент на две части, достаточно установить указатель мыши на место разреза и нажать клавишу «S»).
Последующая обработка
Удалив шум, мы получили только полезный сигнал (речь). Но она динамически не является ровной, то есть, очевидно, что будут какие-нибудь всплески громкости, откровенно тихие места и так далее. Для того, чтобы выровнять ситуацию потребуется компрессор, который мы также можем найти среди устройств, подключенных к Track FX… на автомате. Он имеет достаточно много настроек, и если вы не хотите в них разбираться, проще добавить в Track FX новый модуль WaveHammer, в котором есть уже сформированный пресет под названием Voice.
Если вам не нравится как были записаны свистящие и шипящие звуки, то будет необходимо подключить еще один модуль — DeEsser.
Сведение с музыкальной подложкой
Допустим, а чаще всего это и будет так происходить, вы захотите добавить музыкальный фон. Есть профессиональный и непрофессиональный подход к сведению речи и фона. Мы сделаем профессиональный.
Итак, как было сказано раньше, человеческая речь находится в диапазоне от 100 Гц до 3-4 КГц, а наиболее ярко присутствует в спектре от 800 Гц до 3 КГц. Нам нужно:
А) Приглушить этот диапазон в музыкальной подложке.
Б) Немного выпятить этот же диапазон в речи.
Как это все делается, многие уже догадались, ведь мы заходили в набор плагинов Track FX… и среди всего прочего там есть такой модуль как Track EQ, именно на нем все и делается.
И, кстати, никогда не злоупотребляйте уровнем (высокой громкостью) музыкального фона. Иногда может показаться, что он очень тихий. Это нормально. Зритель должен слушать речь и воспринимать говорящего в качестве главного персонажа. Музыку можно показать только намеком, остальное зритель достроит до необходимого уровня воприятия сам (правила психоакустики). Мало того, если ваша программа делается для ТВ, то стоит знать, что перед выходом в эфир там еще сужают динамический диапазон, в результате подложка будет звучать громче по отношению к голосу.
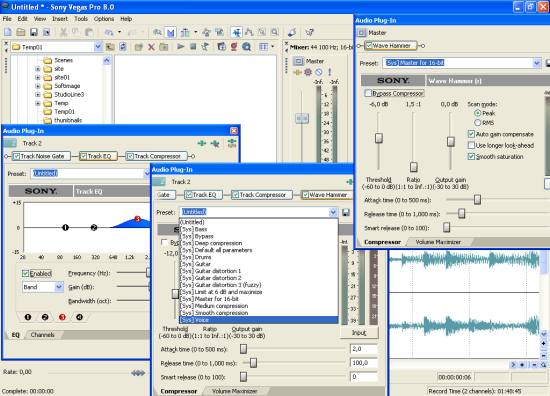
Частотно выделяем голос, выравниваем его динамически, производим финальную обработку.
Финальная обработка
Финальная обработка необходима для того, чтобы все слушалось максимального громко и ровно. В принципе, в рамках Vegas тут достаточно небольшой операции. Есть отдельное окно Mixer, в котором отображен так называемый мастер-выход (общий звуковой выход программы) и все настройки для него. В них мы ничего не регулируем, а просто вызываем окно Master FX… путем нажатия на соответствующую кнопку. В его рамках мы загружаем уже знакомый нам модуль WaveHammer, среди готовых пресетов которого находим Master for 16-bit. Все готово.
Вместо выводов
Конечно, можно бы было рассказать и о подключении к трекам эффектов и управлении их параметрами по графикам огибающих (envelopes), но, если видео-специалист освоит уже написанное, то данный вопрос не вызовет у него сложностей в изучении.
Напомним, что Vegas — это профессиональный продукт для аудиосферы, он, кстати, из нее и пришел в видео. Но многое видеоспециалистам и не нужно на самом деле.


Комментариев нет:
Отправить комментарий